




























































समय - सीमा 297
मानव और उनकी इंद्रियाँ 1079
मानव और उनके आविष्कार 848
भूगोल 272
जीव-जंतु 326
साल 1975 में 19 साल के बिल गेट्स और 22 साल के पॉल एलन ने मिलकर एक ऐसी कंपनी की शुरुआत की थी, जो आज दुनिया की सबसे मूल्यवान कंपनी बन चुकी है। इनकी पहली मुलाकात सिएटल के लेकसाइड स्कूल में हुई थी और कंप्यूटर के प्रति दोनों के भीतर गहरा उत्साह था। उनकी व्यावसायिक साझेदारी ट्रैफ़-ओ-डेटा नामक एक प्रोजेक्ट से शुरू हुई थी, जो व्यावसायिक रूप से तो बहुत सफल नहीं रहा, लेकिन इससे उन्हें सॉफ़्टवेयर विकास का अहम अनुभव मिला। बिल गेट्स के पिता, विलियम हेनरी गेट्स द्वितीय, एक प्रसिद्ध वकील थे और एक बड़ी लॉ फर्म के सह-संस्थापक थे, जहाँ से बिल को कम उम्र में ही व्यापार और कानून की रणनीतिक समझ मिल गई थी। ऑल्टेयर 8800 नाम के पहले व्यावसायिक पर्सनल कंप्यूटर ने वास्तव में इस कंपनी की नींव रखने का काम किया। गेट्स और एलन ने बिना असली कंप्यूटर के, एक मिनीकंप्यूटर पर सिम्युलेटर बनाकर बेसिक प्रोग्रामिंग भाषा का इंटरप्रेटर तैयार किया और पहली ही कोशिश में वह सफल रहा, जिसके बाद 4 अप्रैल 1975 को माइक्रो-सॉफ्ट की स्थापना की गई।
साल 1980 में आईबीएम के साथ हुई साझेदारी ने इस कंपनी को एक नई पहचान और बाज़ार में दबदबा दिया। आईबीएम को अपने पहले पर्सनल कंप्यूटर के लिए एक ऑपरेटिंग सिस्टम चाहिए था और जब डिजिटल रिसर्च के साथ उनकी बातचीत विफल हो गई, तब बिल गेट्स ने यह ज़िम्मेदारी ली। बिल गेट्स ने 75,000 डॉलर में सिएटल कंप्यूटर प्रोडक्ट्स से 86-डोस सिस्टम खरीदा, उसे एमएस-डोस में बदला और आईबीएम को लाइसेंस पर दे दिया। इस सॉफ़्टवेयर को पूरी तरह बेचने के बजाय लाइसेंस पर देना उनकी सबसे बड़ी रणनीतिक जीत थी, क्योंकि इससे वे अन्य पीसी निर्माताओं को भी इसे बेच सकते थे। इसके बाद 1985 में ग्राफिकल इंटरफ़ेस वाला विंडोज़ 1.0 और फिर 1995 में विंडोज़ 95 ने पर्सनल कंप्यूटर की दुनिया में क्रांति ला दी। समय के साथ इस कंपनी ने 2011 में 8.5 अरब डॉलर में स्काइप, 2014 में 2.5 अरब डॉलर में मोजांग (माइनक्राफ्ट), 2016 में 26.2 अरब डॉलर में लिंक्डइन और 2018 में 7.5 अरब डॉलर में गिटहब जैसी विशाल कंपनियों का अधिग्रहण करके अपना साम्राज्य बढ़ाया। साल 2019 में एप्पल और अमेज़ॉन के बाद यह एक ट्रिलियन डॉलर के बाज़ार मूल्य को छूने वाली तीसरी अमेरिकी सार्वजनिक कंपनी बनी। 2022 में 68.7 अरब डॉलर में एक्टिविज़न ब्लिज़र्ड को खरीदने की घोषणा की गई, जिसे अमेरिका और यूरोपीय संघ की लंबी नियामक जांच के बाद अक्टूबर 2023 में पूरा किया जा सका। साल 2019 में इस कंपनी ने एआई की दुनिया में एक बड़ा कदम रखते हुए ओपनएआई में एक अरब डॉलर का निवेश किया, जो आज क्लाउड कंप्यूटिंग (माइक्रोसॉफ्ट एज़्योर) के ज़रिए अमेज़ॉन वेब सर्विसेज़ को कड़ी टक्कर दे रहा है।

क्या आर्टिफिशियल इंटेलिजेंस इंसानों की तरह सोचना आपके डेटा से सीख रहा है?
चैटजीपीटी जैसे लार्ज लैंग्वेज मॉडल को इंसानों की तरह टेक्स्ट को समझने और लिखने के लिए भारी मात्रा में डेटा की आवश्यकता होती है। पारंपरिक सॉफ़्टवेयर के विपरीत, जो इंसानों द्वारा बनाए गए नियमों पर चलते हैं, एआई सिस्टम उदाहरणों से और मशीन लर्निंग की प्रक्रिया के ज़रिए सीखते हैं। इसके प्रशिक्षण डेटा में लाइसेंस प्राप्त सामग्री (जैसे किताबें और शोध डेटासेट), इंसानों द्वारा बनाया गया डेटा और इंटरनेट पर मौजूद सार्वजनिक जानकारी का एक विविध मिश्रण शामिल होता है। सार्वजनिक वेब पर मौजूद अरबों वेब पेज, न्यूज़ आर्टिकल, विकिपीडिया, अकादमिक शोध पत्र और कोड रिपॉज़िटरी से यह डेटा बड़े पैमाने पर क्रॉलिंग के ज़रिए लिया जाता है। इसके अलावा, कंपनियों के आंतरिक कॉर्पोरेट डेटासेट, सोशल मीडिया पोस्ट, प्रोडक्ट रिव्यू और चैट लॉग भी इस प्रशिक्षण का अहम हिस्सा होते हैं। ऑटोनोमस वाहनों (बिना ड्राइवर वाली कारों) के लिए कंप्यूटर-जनरेटेड परिदृश्यों और रोबोटिक्स के लिए सिंथेटिक डेटा का भी तेज़ी से इस्तेमाल हो रहा है।

यह ध्यान रखना ज़रूरी है कि एआई इन सभी दस्तावेजों को सीधे याद करने या सहेजने के बजाय भाषा के पैटर्न, संरचना और संदर्भ को समझता है। इस मॉडल को और अधिक सटीक बनाने के लिए सुपरवाइज़्ड लर्निंग और इंसानी फीडबैक से रीइन्फोर्समेंट लर्निंग जैसी आधुनिक तकनीकों का इस्तेमाल किया जाता है। ओपनएआई की प्रमुख भागीदार, माइक्रोसॉफ्ट इस पूरी प्रक्रिया में अपने माइक्रोसॉफ्ट एज़्योर के ज़रिए क्लाउड कंप्यूटिंग, इंफ्रास्ट्रक्चर और लिंक्डइन जैसे अपने स्वामित्व वाले प्लेटफ़ॉर्म से पेशेवर डेटा की सुविधा प्रदान करती है। हालाँकि, इंटरनेट से सारा डेटा सिर्फ़ ऐसे ही wholesale (थोक में) नहीं उठा लिया जाता; इस डेटा का उपयोग विशिष्ट नीतियों, गोपनीयता मानकों और लाइसेंसिंग समझौतों का सख्ती से पालन करते हुए किया जाता है। ट्रेनिंग से पहले डेटा को साफ़ किया जाता है, डुप्लिकेट हटाए जाते हैं, पक्षपात को कम किया जाता है और व्यक्तिगत जानकारी को अनाम कर दिया जाता है। फिर भी, कॉपीराइट सामग्री के उपयोग, 'भूल जाने के अधिकार' (right to be forgotten) और सांस्कृतिक गोपनीयता जैसी नैतिक चुनौतियां अभी भी एक बड़ी बहस का विषय बनी हुई हैं।
क्या लिंक्डइन पर आपकी पेशेवर जानकारी एआई का ईंधन बन रही है?
माइक्रोसॉफ्ट के स्वामित्व वाला प्लेटफ़ॉर्म लिंक्डइन आज सिर्फ़ एक स्थिर सीवी (CV) डेटाबेस नहीं रह गया है, बल्कि यह एआई के लिए पेशेवर डेटा का एक बहुत बड़ा और बेहद मूल्यवान स्रोत बन चुका है। एक अरब से अधिक सदस्यों वाले इस प्लेटफ़ॉर्म का विशाल डेटा माइक्रोसॉफ्ट के संपूर्ण एंटरप्राइज़ एआई उत्पादों को प्रशिक्षित करने के लिए दोहरे उद्देश्य की पूर्ति करता है। लिंक्डइन एआई आज रिक्रूटर्स के लिए हायरिंग असिस्टेंट, जॉब खोजने वालों के लिए प्रोफ़ाइल ऑप्टिमाइज़ेशन और आम यूज़र्स के लिए पोस्ट जनरेशन जैसे कई बेहतरीन टूल पेश करता है। यह एआई इंजन यूज़र्स की सार्वजनिक पोस्ट, प्रोफ़ाइल डेटा, ग्रुप की गतिविधियों, अपलोड किए गए रेज़्यूमे और फीडबैक से लगातार सीखता है। हालाँकि, कानूनी और गोपनीयता के जोखिमों को कम करने के लिए कंपनी प्राइवेट इनमेल, लॉगिन क्रेडेंशियल, पेमेंट की जानकारी, सैलरी डेटा और किसी विशिष्ट जॉब एप्लिकेशन के डेटा को इस एआई ट्रेनिंग से पूरी तरह बाहर रखती है।
सबसे बड़ी और चौंकाने वाली बात यह है कि डेटा संग्रह का यह नियम सभी यूज़र्स के लिए डिफ़ॉल्ट रूप से चालू (Opt-in by default) रहता है और इसके लिए बाकायदा नवंबर 2025 से नई नीतियां लागू की जा रही हैं। अगर कोई यूज़र अपनी प्राइवेसी सेटिंग में जाकर इस विकल्प को बंद (ऑप्ट-आउट) भी कर देता है, तो भी यह नियम पूर्वव्यापी (retroactive) रूप से लागू नहीं होता। इसका मतलब यह है कि पहले से इस्तेमाल हो चुका डेटा एआई के सिस्टम में हमेशा के लिए मौजूद रहता है। थर्ड-पार्टी ऐप्स (जैसे सीआरएम या सीवी बिल्डर) के साथ लिंक्डइन का जुड़ाव यूज़र्स के डेटा के लीक होने का जोखिम और भी बढ़ा देता है। साल 2021 में लिंक्डइन पर हुई 70 करोड़ यूज़र्स की डेटा स्क्रेपिंग की घटना इस बात का प्रमाण है कि सुरक्षा में सेंध लग सकती है। यूज़र्स भले ही अपने डेटा के मालिक होने का दावा करें, लेकिन प्लेटफ़ॉर्म के यूज़र एग्रीमेंट का व्यापक लाइसेंस कंपनी को बिना किसी मुआवजे के उस सामग्री का उपयोग, संशोधन और वितरण करने की आज़ादी दे देता है। इन सब जोखिमों के बीच 'एटॉमिक मेल' (Atomic Mail) जैसी एंड-टू-एंड एन्क्रिप्शन और ज़ीरो-एक्सेस एन्क्रिप्शन वाली सेवाएं एक सुरक्षित विकल्प के रूप में उभर रही हैं, जो एआई का लाभ तो देती हैं लेकिन कभी भी यूज़र्स के निजी डेटा पर अपने मॉडल को प्रशिक्षित नहीं करतीं।
क्या भारतीय भाषाओं और बोलियों को समझकर एआई और भी चतुर हो रहा है?
एआई को दुनिया भर के यूज़र्स के लिए प्रासंगिक बनाने के लिए माइक्रोसॉफ्ट जैसी कंपनियां क्षेत्रीय भाषाओं का डेटा भी भारी मात्रा में इकट्ठा कर रही हैं। इसके पीछे मुख्य उद्देश्य यह समझना है कि अलग-अलग क्षेत्रों के लोग असल में अपनी दिनचर्या में कैसे बोलते और लिखते हैं। भारतीय भाषाओं के संदर्भ में, इस डेटा संग्रह की शुरुआत अक्सर सरकारी वेबसाइटों, शैक्षिक सामग्री और भाषिनी (Bhashini) जैसे खुले प्लेटफ़ॉर्म से होती है। भाषिनी का प्राथमिक ध्यान इंटरनेट पर भारतीय भाषाओं को अधिक सुलभ और उपयोगी बनाना है। इसके साथ ही, हिंदी, तमिल, बंगाली और अन्य कई क्षेत्रीय भारतीय भाषाओं में सटीक तथा सुव्यवस्थित भाषा डेटा प्राप्त करने के लिए लाइसेंस प्राप्त डेटासेट का उपयोग किया जाता है और नामी विश्वविद्यालयों तथा शोधकर्ताओं के साथ मिलकर काम किया जाता है।
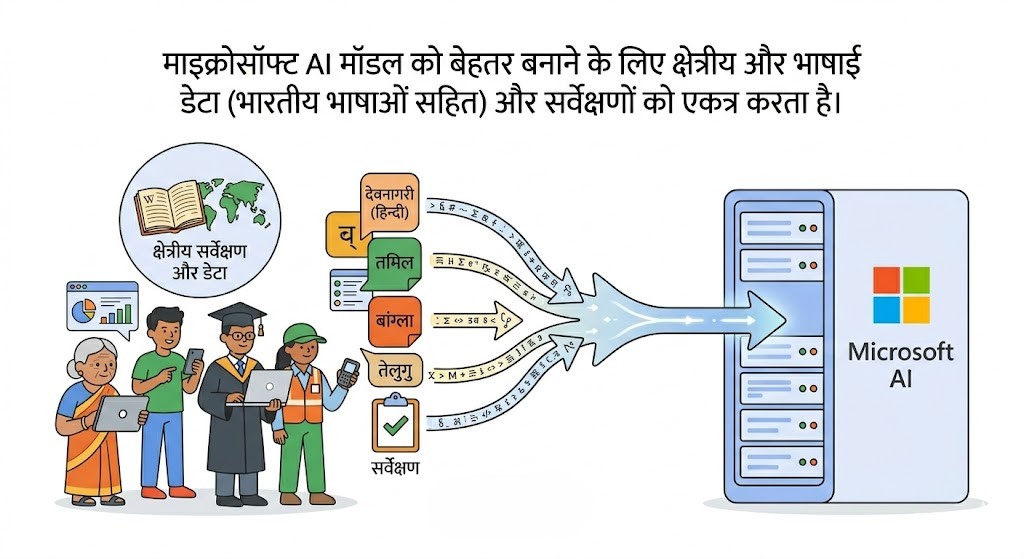
इतना ही नहीं, एआई सिस्टम को वास्तविक यूज़र्स की दैनिक बातचीत से भी बहुत कुछ सिखाया जाता है। उदाहरण के लिए, लोग प्लेटफ़ॉर्म पर कैसे टाइप करते हैं, वे क्या सर्च करते हैं या किस तरह से एक-दूसरे के साथ संवाद करते हैं, यह सब एआई के लिए एक खुली किताब की तरह काम करता है। इसके अलावा, क्षेत्रीय बोलियों या हिंग्लिश (Hinglish) जैसी मिश्रित भाषाओं के इस्तेमाल को गहराई से समझने के लिए कभी-कभी विशेष सर्वे और फीडबैक प्रोग्राम की मदद ली जाती है। इन प्रोग्राम्स में यूज़र्स अपनी मर्ज़ी से अपनी भाषा के उपयोग के बारे में अहम जानकारी साझा करते हैं। यह पूरी डेटा संग्रह प्रक्रिया सख्त गोपनीयता नियमों के तहत पूरी की जाती है, जहाँ यह सुनिश्चित किया जाता है कि उपयोगकर्ताओं की व्यक्तिगत जानकारी पूरी तरह से सुरक्षित रहे या उसे अनाम (anonymized) कर दिया जाए। आसान शब्दों में कहें तो आधिकारिक डेटा, विभिन्न शोध साझेदारियों और वास्तविक दुनिया के उपयोग को मिलाकर माइक्रोसॉफ्ट यह सुनिश्चित करता है कि उसके एआई सिस्टम भारत के अलग-अलग हिस्सों में लोगों के संवाद करने के वास्तविक तरीके को गहराई से समझ सकें और संदर्भ के अनुसार सटीक जवाब उत्पन्न कर सकें।
संदर्भ
1. https://tinyurl.com/23z2xs2u
2. https://tinyurl.com/24jbpu3n
3. https://tinyurl.com/23u24m6g





A. City Readerships (FB + App) - This is the total number of city-based unique readers who reached this specific post from the Prarang Hindi FB page and the Prarang App.
B. Website (Google + Direct) - This is the Total viewership of readers who reached this post directly through their browsers and via Google search.
C. Messaging Subscribers - This is the total viewership from City Portal subscribers who opted for hyperlocal daily messaging and received this post.
D. Total Viewership - This is the Sum of all our readers through FB+App, Website (Google+Direct), Email, WhatsApp, and Instagram who reached this Prarang post/page.
E. The Reach (Viewership) - The reach on the post is updated either on the 6th day from the day of posting or on the completion (Day 31 or 32) of one month from the day of posting.