




























































समय - सीमा 286
मानव और उनकी इंद्रियाँ 1071
मानव और उनके आविष्कार 834
भूगोल 280
जीव-जंतु 326
जौनपुर के इंटरनेट और सोशल मीडिया यूज़र्स के लिए यह जानना बेहद ज़रूरी है कि मेटा ने इस बात की पुष्टि की है कि साल 2007 से लेकर अब तक वयस्कों द्वारा फेसबुक और इंस्टाग्राम पर पब्लिक किए गए सभी टेक्स्ट और फोटो को स्क्रैप किया गया है और कंपनी के आर्टिफ़िशियल इंटेलिजेंस (एआई) मॉडल्स को ट्रेन करने के लिए इस्तेमाल किया गया है। एक तरफ़ सोशल मीडिया लोगों को जोड़ने का काम कर रहा है, वहीं दूसरी तरफ़ यह आपके व्यक्तिगत डेटा और कॉपीराइट सामग्री का उपयोग भी अप्रत्याशित तरीकों से कर रहा है। इंटरनेट की दुनिया में एक रिपोर्ट के मुताबिक़ लगभग 49 प्रतिशत ब्लॉगर्स और सोशल मीडिया यूज़र्स अनजाने में या जानबूझकर कॉपीराइट का उल्लंघन कर चुके हैं।
क्या सोशल मीडिया पर पब्लिश किया गया कंटेंट कॉपीराइट के दायरे में आता है?
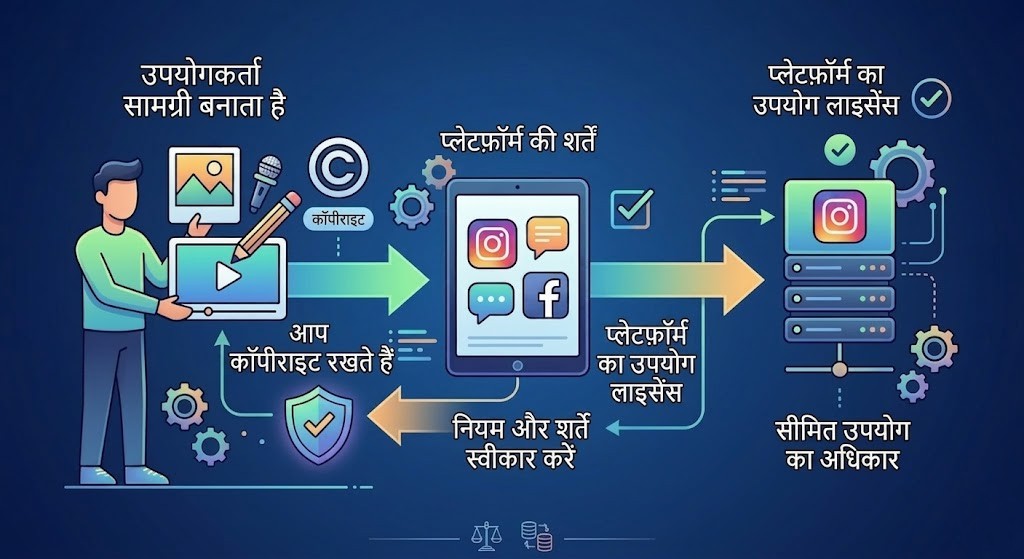
लोगों के बीच यह एक बहुत बड़ी ग़लतफ़हमी है कि सोशल मीडिया साइट्स पर अपना काम या तस्वीरें अपलोड करने का मतलब है कि आप अपना कॉपीराइट खो देते हैं और यदि कोई आपकी अनुमति के बिना आपके काम का उपयोग करता है तो आप कुछ नहीं कर सकते। हक़ीक़त में ऐसा नहीं है। लगभग हर सोशल मीडिया साइट के नियम और शर्तों के अनुसार, जो व्यक्ति कंटेंट बनाता और अपलोड करता है, वह ही अपने काम का असली कॉपीराइट मालिक बना रहता है। जब कोई विज़ुअल वर्क (जैसे फोटो या वीडियो) बनाया जाता है, तो कॉपीराइट स्वचालित रूप से निर्माता को मिल जाता है। आधिकारिक तौर पर कॉपीराइट प्राप्त करने के लिए किसी तस्वीर को रजिस्टर करने की कोई आवश्यकता नहीं होती है।
भारत में कॉपीराइट अधिनियम 1957 के तहत, किसी भी काम पर कॉपीराइट के मालिक को विशेष अधिकार प्राप्त होते हैं, जैसे कि उस काम का उपयोग करना, उसे वितरित करना, या प्रकाशित करना। इसलिए, किसी भी फोटो या वीडियो का कॉपीराइट मालिक ही उसे किसी सोशल मीडिया प्लेटफ़ॉर्म पर अपलोड करने का अधिकार रखता है। यदि कोई और व्यक्ति आपकी अनुमति के बिना आपकी रचना का उपयोग करता है, तो यह कॉपीराइट उल्लंघन माना जाता है। बहुत से लोग यह मानते हैं कि इंटरनेट और सोशल मीडिया पर मौजूद हर चीज़ मुफ़्त है, लेकिन यह सच नहीं है। जब कोई अपना मूल कंटेंट सोशल मीडिया पर पोस्ट करता है, तो वह महज़ एक पब्लिकेशन होता है, ना कि मुफ़्त इस्तेमाल के लिए दिया गया लाइसेंस। "फेयर यूज़" का नियम कुछ विशेष परिस्थितियों (जैसे समीक्षा, समाचार रिपोर्टिंग, या शोध) में अनुमति के बिना काम का उपयोग करने की छूट देता है, लेकिन यह हर परिस्थिति पर लागू नहीं होता।
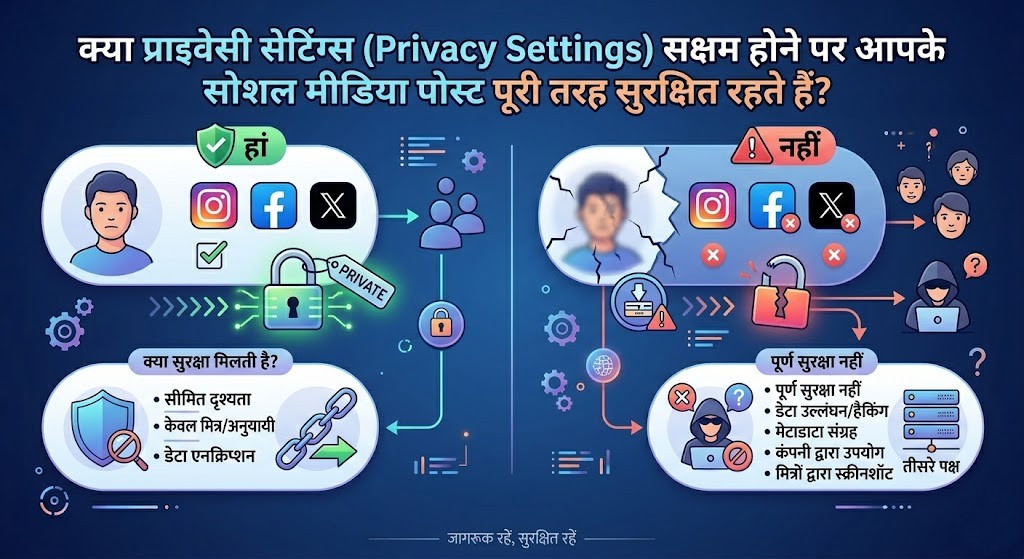
प्लेटफ़ॉर्म के नियमों और प्राइवेसी सेटिंग्स के तहत आपकी ओनरशिप का क्या होता है?
जब आप इंस्टाग्राम या फेसबुक पर कोई फोटो, वीडियो, या कैप्शन पोस्ट करते हैं, तो आप कॉपीराइट के मालिक होते हैं, लेकिन यहाँ एक पेंच है। आप अपनी ओनरशिप तो बरकरार रखते हैं, लेकिन आप इंस्टाग्राम को बहुत बड़े स्तर पर उपयोग के अधिकार भी देते हैं। इसका मतलब है कि आप उन्हें अपने कंटेंट को एक ख़ास तरीके से इस्तेमाल करने की अनुमति देते हैं जिसके लिए वे आपको कोई भुगतान नहीं करते। प्लेटफ़ॉर्म के नियमों के तहत आप उन्हें एक नॉन-एक्सक्लूसिव, रॉयल्टी-फ्री और वर्ल्डवाइड लाइसेंस देते हैं। इसका मतलब यह है कि आप अपनी सामग्री को अन्य जगहों पर भी इस्तेमाल कर सकते हैं, इंस्टाग्राम आपको इस इस्तेमाल के लिए पैसे नहीं देगा, और यह अधिकार दुनिया भर में लागू होगा।
इंस्टाग्राम और फेसबुक जैसे प्लेटफ़ॉर्म अपनी सर्विस चलाने के लिए आपके कंटेंट का उपयोग कर सकते हैं, उसे वितरित कर सकते हैं, बदल सकते हैं, प्रदर्शित कर सकते हैं और यहां तक कि उससे जुड़े अन्य काम भी बना सकते हैं। जब आप अपना कंटेंट या अकाउंट डिलीट करते हैं तो यह लाइसेंस आम तौर पर समाप्त हो जाता है। लेकिन, यदि किसी अन्य यूज़र ने आपके कंटेंट को शेयर या एम्बेड किया है, और उन्होंने उसे डिलीट नहीं किया है, तो प्लेटफ़ॉर्म का वह लाइसेंस जारी रह सकता है। फेसबुक के नियम यह कहते हैं कि यदि ओरिजिनल यूज़र अपना कंटेंट हटा भी दे, तो भी लाइसेंस तब तक बना रहेगा जब तक कि उस कंटेंट को शेयर करने वाले बाकी सभी लोग उसे डिलीट न कर दें। इस तरह वायरल फोटो या वीडियो के लिए यह लाइसेंस अनिश्चित काल तक चल सकता है। एक्स (पूर्व में ट्विटर) के मामले में तो यह और भी आगे जाता है, जहाँ अकाउंट बंद करने के बाद भी अपलोड किए गए कंटेंट पर उपयोग का लाइसेंस हमेशा के लिए बना रहता है।
एआई सिस्टम को कैसे ट्रेन किया जाता है और इसके कॉपीराइट से जुड़े ख़तरे क्या हैं?
आजकल जनरेटिव एआई मॉडल, जैसे कि लार्ज लैंग्वेज मॉडल (एलएलएम) और इमेज जनरेटर, मशीन लर्निंग तकनीकों के माध्यम से विकसित किए जा रहे हैं। इन मॉडल्स की कार्यक्षमता को बेहतर बनाने के लिए इन्हें बहुत बड़े डेटासेट्स पर ट्रेन किया जाता है। इनमें से कई डेटासेट्स में कॉपीराइट वाला काम शामिल हो सकता है। ट्रेनिंग की प्रक्रिया में कई चरण होते हैं, जिसमें जनरल पैटर्न सीखने के लिए प्री-ट्रेनिंग, और विशिष्ट कार्यों के लिए पोस्ट-ट्रेनिंग या फाइन-ट्यूनिंग शामिल होती है। डेवलपर्स भारी मात्रा में डेटा को स्क्रैप करते हैं, फ़िल्टर करते हैं और इकट्ठा करते हैं, जिस पर एआई मॉडल भविष्यवाणी करना सीखते हैं।
ट्रेनिंग डेटासेट्स के लिए कॉपीराइट किए गए कार्यों को डाउनलोड करने, कॉपी करने और मॉडिफाई करने से कॉपीराइट के नियमों पर असर पड़ता है। इसके अलावा, एआई सिस्टम ऐसा कंटेंट आउटपुट कर सकते हैं जो कॉपीराइट किए गए काम की बिल्कुल नकल करता हो या उससे बहुत मिलता-जुलता हो। रिट्रीवल-ऑगमेंटेड जनरेशन (रैग) का उपयोग करके जनरेशन के समय बाहरी कंटेंट को शामिल करना भी उल्लंघन के सवाल खड़े कर सकता है। अमेरिकी कॉपीराइट कार्यालय की रिपोर्ट के अनुसार, एआई द्वारा उपयोग में "फेयर यूज़" (उचित उपयोग) एक बचाव हो सकता है, लेकिन यह हर स्थिति में लागू नहीं होता है। यदि एआई का आउटपुट ओरिजिनल काम से प्रतिस्पर्धा करता है या बाज़ार में उसकी जगह लेने लगता है, तो वह फेयर यूज़ के अंतर्गत नहीं आएगा।
क्या आप अपना डेटा एआई ट्रेनिंग के लिए इस्तेमाल होने से रोक सकते हैं?
सोशल मीडिया कंपनियाँ अक्सर हमारी अनुमति के बिना एआई मॉडल को ट्रेन करने के लिए हमारे डेटा का उपयोग कर रही हैं। यूरोपीय संघ में जनरल डेटा प्रोटेक्शन रेगुलेशन (जीडीपीआर) लागू है, जिसकी वजह से मेटा को यूरोपीय उपभोक्ताओं को एक नोटिस भेजना पड़ा और उन्हें डेटा कलेक्शन से बाहर निकलने (ऑप्ट-आउट) का विकल्प देना पड़ा। लेकिन अमेरिका या कई अन्य देशों में इस तरह का कोई कड़ा राष्ट्रीय कानून नहीं है जो सोशल मीडिया कंपनियों को एआई मॉडल ट्रेनिंग के लिए यूज़र्स का डेटा इस्तेमाल करने से रोक सके। हालाँकि, आप अपनी प्राइवेसी सेटिंग्स बदलकर अपने डेटा को भविष्य में इस्तेमाल होने से कुछ हद तक बचा सकते हैं।
इंस्टाग्राम पर अपना डेटा एआई ट्रेनिंग से बचाने का एकमात्र वास्तविक तरीका यह है कि आप अपने अकाउंट को प्राइवेट कर लें। मेटा ने कहा है कि वह प्राइवेट अकाउंट्स से डेटा या जानकारी का उपयोग नहीं करेगा। इसके लिए अपनी प्रोफ़ाइल पर जाएँ, सेटिंग आइकॉन पर क्लिक करें, और 'अकाउंट प्राइवेसी' में जाकर 'प्राइवेट अकाउंट' के स्विच को ऑन कर दें। इसी तरह फेसबुक पर भी आपको अपनी पोस्ट्स की विज़िबिलिटी को 'पब्लिक' से हटाकर 'फ्रेंड्स' पर सेट करना होगा। 'सेटिंग्स एंड प्राइवेसी' में जाकर 'ऑडियंस एंड विज़िबिलिटी' के तहत 'पोस्ट्स' चुनें, और "आपकी भविष्य की पोस्ट कौन देख सकता है?" को 'फ्रेंड्स' कर दें।
एक्स (ट्विटर) ने भी नए नियम लागू किए हैं जिसमें यूज़र्स का डेटा 'ग्रोक' (Grok) जैसे एआई को ट्रेन करने के लिए इस्तेमाल किया जा रहा है। इसे रोकने के लिए आप सेटिंग्स में जाकर 'प्राइवेसी एंड सेफ्टी' पर क्लिक करें, फिर 'Grok & Third-party Collaborators' को चुनें और बॉक्स को अनचेक कर दें। लिंक्डइन पर भी 'सेटिंग्स एंड प्राइवेसी' में जाकर 'डेटा प्राइवेसी' चुनें, और 'Data for Generative AI Improvement' के स्विच को ऑफ़ कर दें। चैटजीपीटी में भी मुफ़्त अकाउंट वाले यूज़र्स की चैट का डेटा इस्तेमाल होता है। इसे बंद करने के लिए चैटजीपीटी की सेटिंग्स में 'डेटा कंट्रोल्स' पर जाएँ और 'Improve the model for everyone' स्विच को बंद कर दें। याद रखें कि ये सेटिंग्स केवल भविष्य के डेटा को बचाएंगी, आपके पिछले इस्तेमाल हो चुके डेटा को नहीं।
संदर्भ
1. https://tinyurl.com/2cklyk36
2. https://tinyurl.com/29gopexr
3. https://tinyurl.com/2d4pul3j
4. https://tinyurl.com/22vmml2f
5. https://tinyurl.com/2xoqnx9y
6. https://tinyurl.com/2c9g7g4j




A. City Readerships (FB + App) - This is the total number of city-based unique readers who reached this specific post from the Prarang Hindi FB page and the Prarang App.
B. Website (Google + Direct) - This is the Total viewership of readers who reached this post directly through their browsers and via Google search.
C. Messaging Subscribers - This is the total viewership from City Portal subscribers who opted for hyperlocal daily messaging and received this post.
D. Total Viewership - This is the Sum of all our readers through FB+App, Website (Google+Direct), Email, WhatsApp, and Instagram who reached this Prarang post/page.
E. The Reach (Viewership) - The reach on the post is updated either on the 6th day from the day of posting or on the completion (Day 31 or 32) of one month from the day of posting.