




























































समय - सीमा 274
मानव और उनकी इंद्रियाँ 1089
मानव और उनके आविष्कार 853
भूगोल 257
जीव-जंतु 320
क्या आप जानते हैं कि एक एंड्रॉयड स्मार्टफ़ोन जब बिल्कुल खाली रखा होता है और उसका कोई इस्तेमाल नहीं हो रहा होता, तब भी वह हर बारह घंटे में एक मेगाबाइट डेटा गूगल के सर्वर पर भेजता है? यह चौंकाने वाला आंकड़ा उस कंपनी का है जिसने 1995 में स्टैनफ़ोर्ड यूनिवर्सिटी के एक हॉस्टल के कमरे से अपनी शुरुआत की थी। आज वह कंपनी न केवल दुनिया भर की जानकारी को व्यवस्थित कर रही है, बल्कि हमारे डिजिटल जीवन के हर कदम को ट्रैक भी कर रही है। आइए विस्तार से समझते हैं कि कैसे एक छोटा सा सर्च इंजन आज दुनिया की सबसे बड़ी डेटा और आर्टिफिशियल इंटेलिजेंस की ताकत बन चुका है और कैसे यह ओपन नॉलेज के सबसे बड़े स्रोत विकिपीडिया के अस्तित्व के लिए एक नई चुनौती पैदा कर रहा है।
क्या एक गैराज से शुरू हुआ सफर आज पूरी दुनिया को चला रहा है?
गूगल की कहानी की शुरुआत साल 1995 में स्टैनफ़ोर्ड यूनिवर्सिटी से होती है, जहाँ लैरी पेज और सर्गेई ब्रिन की पहली मुलाकात हुई थी। कुछ लोगों का कहना है कि अपनी पहली मुलाकात में वे लगभग हर बात पर असहमत थे, लेकिन अगले ही साल उन्होंने एक साझेदारी कर ली। अपने हॉस्टल के कमरों से काम करते हुए, उन्होंने एक ऐसा सर्च इंजन बनाया जो वर्ल्ड वाइड वेब पर पेजों का महत्व तय करने के लिए लिंक्स का इस्तेमाल करता था। शुरुआत में उन्होंने इस सर्च इंजन का नाम बैकरब रखा था। कुछ समय बाद इसका नाम बदलकर गूगल कर दिया गया, जो असल में गणित के एक शब्द का बिगड़ा हुआ रूप था जिसमें एक के बाद सौ शून्य होते हैं। अगस्त 1998 में सन माइक्रोसिस्टम्स के सह-संस्थापक एंडी बेचटोल्शेम ने लैरी और सर्गेई को एक लाख डॉलर का चेक दिया और आधिकारिक तौर पर गूगल इंक का जन्म हुआ। इस निवेश के बाद टीम हॉस्टल से निकलकर कैलिफ़ोर्निया के मेनलो पार्क में सुज़ैन वोज्स्की के गैराज में शिफ्ट हो गई। उस गैराज में भारी-भरकम कंप्यूटर, एक पिंग पोंग टेबल और नीले रंग का कालीन उनके शुरुआती दिनों की पहचान हुआ करते थे। समय के साथ कंपनी तेज़ी से बढ़ी और गैराज से निकलकर कैलिफ़ोर्निया के माउंटेन व्यू स्थित अपने मौजूदा मुख्यालय 'द गूगलप्लेक्स' में पहुँच गई। आज गूगल यूट्यूब, एंड्रॉयड, जीमेल और गूगल सर्च जैसे सैकड़ों उत्पाद बनाता है जिनका इस्तेमाल दुनिया भर के अरबों लोग करते हैं।
क्या आपका हर कदम और क्लिक डेटाबेस में दर्ज हो रहा है?
गूगल आज इंटरनेट की दुनिया में हर जगह मौजूद है और इसका डेटा कलेक्शन मॉडल बेहद विशाल है। ट्रिनिटी कॉलेज के एक शोधकर्ता डग लेह के अनुसार, गूगल का एंड्रॉयड ऑपरेटिंग सिस्टम एप्पल के आईओएस सिस्टम के मुकाबले बीस गुना ज़्यादा डेटा इकट्ठा करता है। गूगल के पास आपकी यूट्यूब हिस्ट्री, जीमेल के ईमेल, गूगल ड्राइव की फ़ाइलें, गूगल मैप्स की लोकेशन्स और गूगल कैलेंडर के शेड्यूल जैसी हर चीज़ की सीधी पहुँच है। जब आप कोई गूगल अकाउंट बनाते हैं, तो आप अपना फोन नंबर और क्रेडिट कार्ड जैसी निजी जानकारी देते हैं। गूगल की अपनी प्राइवेसी पॉलिसी के मुताबिक, जब आप उनकी सेवाओं का इस्तेमाल करते हुए कोई कंटेंट बनाते हैं, अपलोड करते हैं या प्राप्त करते हैं, तो कंपनी उसे कलेक्ट करती है। इसके अलावा, गूगल आपके ब्राउज़र का प्रकार, ऑपरेटिंग सिस्टम, मोबाइल नेटवर्क, आईपी एड्रेस और क्रैश रिपोर्ट भी जमा करता है। आपकी लोकेशन का पता लगाने के लिए गूगल सिर्फ़ जीपीएस पर निर्भर नहीं है, बल्कि वह आपके आस-पास मौजूद पब्लिक वाई-फ़ाई और सेल टावर का भी इस्तेमाल करता है। साल 2005 में वेब स्टैटिस्टिक्स कंपनी अर्चिन को खरीदने के बाद गूगल ने वेब एनालिटिक्स का भी लोकतंत्रीकरण कर दिया। वेबसाइट के मालिकों को गूगल एनालिटिक्स के ज़रिए यूज़र्स की उम्र, लिंग और रुचियों का जनसांख्यिकीय डेटा भी मिलता है। हालाँकि गूगल इस भारी भरकम डेटा का इस्तेमाल अपने विज्ञापनों को ज़्यादा सटीक बनाने और व्यक्तिगत अनुभव को बेहतर करने के लिए करता है।

क्या आपकी निजी जानकारी अब आर्टिफिशियल इंटेलिजेंस को ट्रेन कर रही है?
डेटा जुटाने की इसी कड़ी में अब एक नया अध्याय आर्टिफिशियल इंटेलिजेंस का जुड़ गया है। गूगल ने हाल ही में अपनी प्राइवेसी पॉलिसी में बदलाव करते हुए साफ़ कर दिया है कि वह इंटरनेट पर मौजूद सभी सार्वजनिक जानकारी का इस्तेमाल अपने एआई सिस्टम जैसे गूगल ट्रांसलेट, बार्ड और क्लाउड एआई को ट्रेन करने के लिए करेगा। क्या जीमेल का निजी डेटा भी एआई को ट्रेन करने के लिए इस्तेमाल हो रहा है, यह सवाल अभी भी रहस्य बना हुआ है। जब गूगल के चैटबॉट बार्ड से यह पूछा गया तो उसने खुद दावा किया था कि उसे जीमेल के डेटा से ट्रेन किया गया है, लेकिन गूगल ने तुरंत इसका खंडन करते हुए कहा कि बार्ड लार्ज लैंग्वेज मॉडल पर आधारित है जो गलतियां कर सकता है और इसे जीमेल डेटा पर ट्रेन नहीं किया गया है। विशेषज्ञों का मानना है कि बार्ड और जेमिनी जैसे टूल्स गूगल की एक कोशिश हैं ताकि वह मुफ्त में उपलब्ध जानकारी पर कब्ज़ा कर सके और उसे अपने फायदे के लिए इस्तेमाल कर सके। पारंपरिक गूगल सर्च में जहाँ उपयोगकर्ताओं को जानकारी का मूल स्रोत देखने को मिलता था, वहीं अब चैटजीपीटी और बार्ड जैसे टूल्स सीधे जवाब देते हैं और लोगों से स्रोत जाँचने का विकल्प छीन लेते हैं। यह बिल्कुल उसी तरह है जब गूगल ने एएमपी प्रोजेक्ट शुरू किया था ताकि यूज़र्स ज़्यादा से ज़्यादा समय उनके ही सिस्टम पर बिताएं और बाहर के लिंक्स पर क्लिक न करें। 
क्या दुनिया का सबसे बड़ा ज्ञानकोष सिर्फ गूगल का ईंधन बन रहा है?
गूगल के इस विशाल एआई और सर्च इकोसिस्टम को शक्ति देने में विकिपीडिया का सबसे बड़ा योगदान रहा है। ऐतिहासिक रूप से गूगल ने विकिपीडिया के ऑर्गेनिक ट्रैफ़िक का लगभग 80 प्रतिशत से ज़्यादा हिस्सा प्रदान किया है। साल 2012 में जब गूगल ने अपना नॉलेज ग्राफ़ लॉन्च किया, तो उसने खोज परिणामों में सीधे जानकारी दिखाने के लिए विकिपीडिया के डेटा का भारी इस्तेमाल किया। इसके बाद 2014 के आसपास शुरू हुए 'फीचर्ड स्निपेट्स' में भी विकिपीडिया की सामग्री का प्रमुखता से उपयोग हुआ, जिसके तहत लगभग 99 प्रतिशत स्निपेट्स टॉप सर्च रिज़ल्ट्स से आते हैं। गूगल ने इस साझेदारी को बनाए रखने के लिए 2010 और 2019 में विकिमीडिया फाउंडेशन को बीस-बीस लाख डॉलर के अनुदान भी दिए थे। लेकिन 2022 में दोनों के बीच एक बड़ा व्यावसायिक बदलाव आया, जब गूगल 'विकिमीडिया एंटरप्राइज़' का एक भुगतान करने वाला ग्राहक बन गया। इसके तहत गूगल को विकिपीडिया के डेटाबेस का सीधा और रियल-टाइम एक्सेस मिलता है ताकि वह अपने सर्च उत्पादों में बिना किसी देरी के एकदम ताज़ा जानकारी डाल सके। हालांकि गूगल के एल्गोरिदम पर निर्भरता के अपने नुकसान भी हैं; मैनहट्टन इंस्टीट्यूट के एक हालिया अध्ययन से पता चला है कि विकिपीडिया के लेखों में अक्सर राजनीतिक झुकाव होता है और गूगल के सर्च एल्गोरिदम बिना किसी चेतावनी के इसी जानकारी को लाखों लोगों तक पहुँचाकर उसे एक निष्पक्ष तथ्य के रूप में स्थापित कर देते हैं।
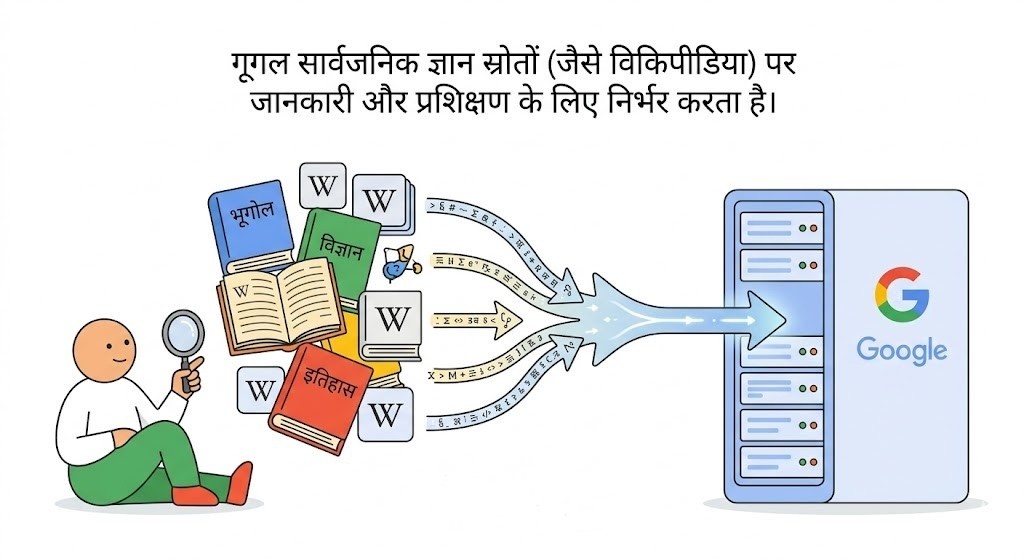
क्या एआई के दौर में ओपन नॉलेज और डेटा स्वामित्व का भविष्य खतरे में है?
आज बिग टेक कंपनियों और यूज़र्स के बीच डेटा पर नियंत्रण और ओपन नॉलेज के भविष्य को लेकर एक बड़ी जंग छिड़ गई है। विकिमीडिया फाउंडेशन की एक रिपोर्ट के अनुसार, साल 2025 में विकिपीडिया पर इंसानों द्वारा देखे जाने वाले पेजों की संख्या में 8 प्रतिशत की गिरावट आई है। यह गिरावट सीधे तौर पर गूगल के 'एआई ओवरव्यूज़' की वजह से है, जो मई 2024 में पूरी तरह लागू हुआ था। एआई ओवरव्यूज़ यूज़र्स को सर्च पेज पर ही पूरी जानकारी का सारांश दे देता है, जिससे लोग मूल वेबसाइट के लिंक पर क्लिक ही नहीं करते। प्यू रिसर्च सेंटर के एक विश्लेषण में पाया गया कि गूगल के एआई सारांश देखने वाले यूज़र्स में से केवल एक प्रतिशत ही बाहरी लिंक पर क्लिक करते हैं। इस 'ज़ीरो-क्लिक' सर्च की वजह से विकिपीडिया जैसे प्लेटफ़ॉर्म्स पर बड़ा वित्तीय संकट मंडराने लगा है क्योंकि उनका पूरा संचालन चंदे पर निर्भर करता है, और जब वेबसाइट पर लोग कम आएंगे तो चंदा भी कम मिलेगा। जानकार इसे 'फ़्री राइडिंग' कहते हैं, जहाँ गूगल विकिपीडिया की सामग्री से उत्तर बनाकर विज्ञापन का राजस्व कमाता है, लेकिन ज्ञान को तैयार करने का पूरा बोझ मुफ्त में काम करने वाले स्वयंसेवकों पर छोड़ देता है। एआई के इस युग में यह साफ़ होता जा रहा है कि ज्ञान के विकेंद्रीकरण का मॉडल खतरे में है, क्योंकि सारी ताकत अब कुछ चुनिंदा सर्च इंजन और एआई कंपनियों के हाथों में सिमटती जा रही है।
संदर्भ
1. https://tinyurl.com/262zqm3m
2. https://tinyurl.com/ycar2vd7
3. https://tinyurl.com/22elvnrt
4. https://tinyurl.com/25lwdnh4
5. https://tinyurl.com/25ydbsts





A. City Readerships (FB + App) - This is the total number of city-based unique readers who reached this specific post from the Prarang Hindi FB page and the Prarang App.
B. Website (Google + Direct) - This is the Total viewership of readers who reached this post directly through their browsers and via Google search.
C. Messaging Subscribers - This is the total viewership from City Portal subscribers who opted for hyperlocal daily messaging and received this post.
D. Total Viewership - This is the Sum of all our readers through FB+App, Website (Google+Direct), Email, WhatsApp, and Instagram who reached this Prarang post/page.
E. The Reach (Viewership) - The reach on the post is updated either on the 6th day from the day of posting or on the completion (Day 31 or 32) of one month from the day of posting.