




























































समय - सीमा 280
मानव और उनकी इंद्रियाँ 1082
मानव और उनके आविष्कार 841
भूगोल 274
जीव-जंतु 330
रामपुर हो या दुनिया का कोई अन्य शहर, आज हर किसी के हाथ में मौजूद स्मार्टफ़ोन पर तेज़ी से खबरें पहुँचाने वाले प्लेटफ़ॉर्म की कहानी एक छोटे से पॉडकास्टिंग प्रोजेक्ट से शुरू हुई थी। साल 2006 में जैक डॉर्सी, इवान विलियम्स, बिज़ स्टोन और नोआ ग्लास ने एक ऐसे प्लेटफ़ॉर्म की कल्पना की जहाँ लोग रीयल-टाइम में अपना स्टेटस साझा कर सकें। इसकी प्रेरणा एसएमएस टेक्स्ट मैसेजिंग से मिली थी और उस समय टेक्स्ट मैसेज की अधिकतम सीमा 140 अक्षर होने के कारण, इस नए प्लेटफ़ॉर्म पर भी पोस्ट की सीमा 140 अक्षर ही तय की गई थी। 21 मार्च 2006 को जैक डॉर्सी ने अपना पहला संदेश लिखा था जिसमें उन्होंने कहा था कि वह अपना 'twttr' सेट कर रहे हैं। साल 2007 में सैन डिएगो में लगी भयानक आग के दौरान लोगों ने हैशटैग का इस्तेमाल करके रीयल-टाइम जानकारी साझा की थी और यहीं से हैशटैग एक ताक़तवर टूल बन गया। इसके बाद 2009 में ईरान के राष्ट्रपति चुनाव के दौरान हुए विरोध प्रदर्शनों में भी इस प्लेटफ़ॉर्म ने ज़मीनी स्तर पर संचार के लिए एक महत्वपूर्ण भूमिका निभाई थी ।

इस प्लेटफ़ॉर्म ने दुनिया भर की राजनीति और संस्कृति को आकार दिया और 2013 में यह पब्लिक कंपनी बन गई। लेकिन सबसे बड़ा बदलाव तब आया जब दक्षिण अफ़्रीका में जन्मे अमेरिकी उद्यमी एलन मस्क ने अक्टूबर 2022 में 44 अरब डॉलर में इस कंपनी का अधिग्रहण कर लिया। मस्क ने इसके बाद हज़ारों कर्मचारियों को नौकरी से निकाल दिया और कई निलंबित खातों को बहाल कर दिया। अप्रैल 2023 में मस्क ने आधिकारिक तौर पर इस कंपनी का नाम बदलकर 'एक्स' कर दिया और इसके पुराने नाम और पहचान को पूरी तरह ख़त्म कर दिया। मस्क का उद्देश्य इसे चीन के वीचैट की तर्ज़ पर एक 'एवरीथिंग ऐप' बनाना है, जहाँ लोग न सिर्फ़ सोशल मीडिया का इस्तेमाल कर सकें बल्कि शॉपिंग और वित्तीय लेन-देन भी कर सकें।
क्या आपकी हर पोस्ट और भावनाएं लार्ज लैंग्वेज मॉडल के लिए सोने की खान हैं?
आज के दौर में मशीन लर्निंग और एआई सिस्टम को प्रशिक्षित करने के लिए विशाल डेटा की तलाश की जा रही है और 'एक्स' पर हर दिन साझा होने वाले लाखों पोस्ट इस काम के लिए सोने की खान साबित हो रहे हैं। 'एक्स' सिर्फ़ एक साझा मंच नहीं है बल्कि यह अनगिनत छोटे समुदायों का समूह है। उदाहरण के लिए 'क्रिप्टो एक्स' की भाषा 'मेडिकल एक्स' या 'एकेडमिक एक्स' से बिल्कुल अलग होती है। लार्ज लैंग्वेज मॉडल जब इस विविधतापूर्ण डेटा से सीखते हैं तो वे अलग-अलग विषयों के मुश्किल शब्दों और संदर्भों को आसानी से समझ लेते हैं। इसका एक वास्तविक उदाहरण स्टैनफ़ोर्ड यूनिवर्सिटी के शोधकर्ताओं का है, जिन्होंने 'मेडिकल एक्स' से कैंसर और अन्य बीमारियों की दो लाख से ज़्यादा नैदानिक तस्वीरें इकट्ठा कीं और उनसे एक ऐसा एआई मॉडल तैयार किया जो नई तस्वीरों को देखकर सटीक निदान कर सकता है ।
सिर्फ़ टेक्स्ट ही नहीं बल्कि यूज़र द्वारा बनाए गए वीडियो भी इस ट्रेनिंग के लिए बेहद अहम हैं। आज एआई कंपनियां यूट्यूब और अन्य क्रिएटर्स से उनके अनपब्लिश्ड वीडियो हज़ारों डॉलर में खरीद रही हैं क्योंकि यह विशेष डेटा कहीं और उपलब्ध नहीं होता। इस तरह के वीडियो में बिना स्क्रिप्ट वाले असली इंसान के भाव, हाव-भाव और बोलने के तरीके मौजूद होते हैं जो एआई को इंसानों की तरह व्यवहार करना सिखाते हैं। 'एक्स' पर मौजूद भावनाओं का भी एआई ट्रेनिंग में बड़ा महत्व है जिससे मॉडल इंसानी भावनाओं को पहचानना सीखते हैं। हालाँकि इस विशाल डेटा में लगभग 15 प्रतिशत खाते बॉट्स के हैं जो स्पैम और निम्न स्तर का कंटेंट फैलाते हैं, इसलिए एआई को असली और नकली जानकारी के बीच फ़र्क करना भी सिखाया जा रहा है। साल 2016 में माइक्रोसॉफ्ट ने 'टे' नाम का एक चैटबॉट जारी किया था जिसे ट्विटर के यूज़र्स से बातचीत करके सीखना था, लेकिन कुछ ही घंटों में शरारती तत्वों ने उसे आक्रामक बातें सिखा दीं और माइक्रोसॉफ्ट को उसे बंद करना पड़ा। यह घटना दिखाती है कि खुले प्लेटफ़ॉर्म का डेटा बिना फ़िल्टर के इस्तेमाल करना कितना जोखिम भरा हो सकता है।

क्या ग्रोक एआई इंटरनेट का सबसे विद्रोही और बेबाक चैटबॉट है?
एलन मस्क ने 'एक्स' को सिर्फ़ एक सोशल मीडिया ऐप तक सीमित नहीं रखा है बल्कि 'एक्स एआई' कंपनी बनाकर इसमें 'ग्रोक एआई' को गहराई से जोड़ दिया है। ग्रोक अन्य एआई मॉडल से बिल्कुल अलग है क्योंकि इसके पास 'एक्स' के विशाल रीयल-टाइम डेटाबेस की सीधी पहुँच है। इसका मतलब यह है कि दुनिया भर में जो भी ब्रेकिंग न्यूज़ या रुझान चल रहे हैं, ग्रोक उन्हें तुरंत समझ सकता है। मस्क के अनुसार यह एआई राजनीतिक शुद्धता से परे जाकर 'सच्चाई की खोज' करने वाला मॉडल है। जब अन्य एआई मॉडल विवादित या मसालेदार सवालों का जवाब देने से कतराते हैं, तब ग्रोक अपने विद्रोही अंदाज़ और थोड़े मज़ाकिया लहज़े में उन सवालों के जवाब देता है। ग्रोक का यह व्यक्तित्व एलन मस्क की पसंदीदा किताब 'द हिचहाइकर्स गाइड टू द गैलेक्सी' (The Hitchhikers Guide to the Galaxy) से प्रेरित है। ग्रोक नाम खुद 1961 के मशहूर विज्ञान कथा उपन्यास 'स्ट्रेंजर इन ए स्ट्रेंज लैंड' (Strangers in a strange land) से लिया गया है, जिसमें एक मंगल ग्रह का वासी किसी चीज़ की गहरी समझ को दर्शाने के लिए इस शब्द का इस्तेमाल करता है ।
इसकी बेबाकी का अंदाज़ा इसी बात से लगाया जा सकता है कि जब एक यूज़र ने इससे कोकीन बनाने का तरीका पूछा तो इसने शैक्षिक उद्देश्यों का हवाला देते हुए चरणबद्ध तरीके से जवाब दिया और यहाँ तक कहा कि उम्मीद है आप ख़ुद को उड़ा नहीं लेंगे या गिरफ़्तार नहीं होंगे। इसे दुनिया के सबसे बड़े सुपरकंप्यूटर 'कोलॉसस' पर प्रशिक्षित किया गया है जिसमें दो लाख एनवीडिया हॉपर जीपीयू लगे हैं। फ़रवरी 2025 में ग्रोक 3 और जुलाई 2025 में ग्रोक 4 रिलीज़ किया गया था, जिसने कई परीक्षाओं और गणित के पैमानों पर चैटजीपीटी को भी पीछे छोड़ दिया है। इसके अलावा जुलाई 2025 में ही अमेरिका के रक्षा विभाग ने 'एक्स एआई' के साथ 20 करोड़ डॉलर का करार किया है ताकि सरकारी सेवाओं को और अधिक तेज़ बनाया जा सके। ग्रोक 'एक्स' को एक ज़्यादा समझदार प्लेटफ़ॉर्म बना रहा है जो गलत जानकारी की पहचान करने और यूज़र को उनके पसंद का कंटेंट परोसने का काम कर रहा है।
क्या आपकी निजता की कीमत पर सोशल मीडिया कंपनियां अपनी एआई की तिजोरियां भर रही हैं?
जैसे-जैसे जनरेटिव एआई की दौड़ तेज़ हो रही है, डेटा की निजता और स्वामित्व को लेकर गंभीर चिंताएं भी पैदा हो रही हैं। सच्चाई यह है कि सोशल मीडिया पर पोस्ट किया गया लगभग हर यूज़र जनरेटेड कंटेंट व्यक्तिगत डेटा से भरा होता है। फिर भी बड़ी टेक कंपनियां इस कंटेंट का इस्तेमाल बेझिझक कर रही हैं क्योंकि मौजूदा कानूनी ढांचे के तहत इंटरनेट पर डाली गई जानकारी को सार्वजनिक माना जाता है, चाहे आपने उसमें अपने जीवन की कितनी भी निजी बातें क्यों न लिखी हों। कानूनी विशेषज्ञों का तर्क है कि यूज़र के डेटा का यह मौजूदा व्यवहार पूरी तरह से उपभोक्ता विरोधी है क्योंकि यह आज की तकनीकी प्रगति और ऑनलाइन नियमों की अनदेखी करता है ।
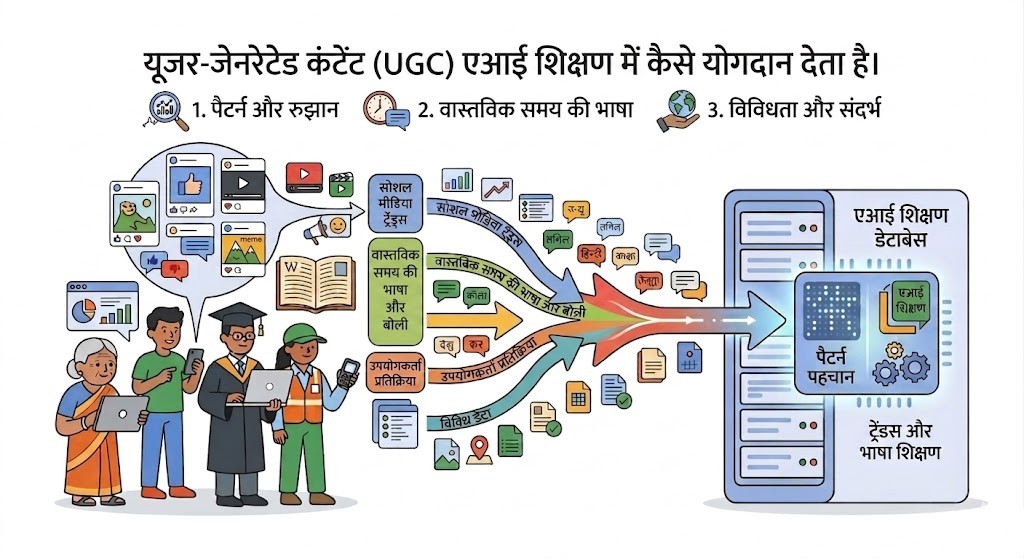
जब बड़े प्लेटफ़ॉर्म किसी यूज़र के कंटेंट का उसकी स्पष्ट जानकारी या सहमति के बिना एआई को प्रशिक्षित करने के लिए दोहन करते हैं, तो यह निजता का सीधा उल्लंघन महसूस होता है। यूज़र्स ने अपनी बातें एक अलग संदर्भ में दोस्तों या समाज के लिए लिखी थीं, लेकिन अब उसी जानकारी का इस्तेमाल किसी मशीन को चतुर बनाने और कंपनी का मुनाफ़ा बढ़ाने के लिए किया जा रहा है। सबसे बड़ी समस्या यह है कि यूज़र्स को एक मजबूरी भरी दुविधा में डाल दिया गया है। उनके पास केवल दो ही विकल्प बचते हैं, या तो वे सेवा की शर्तों को चुपचाप मान लें और अपना डेटा एआई ट्रेनिंग के लिए दे दें, या फिर उस ऑनलाइन सेवा का इस्तेमाल करना ही छोड़ दें। यह एक ऐसी व्यवस्था है जो बड़ी टेक कंपनियों के हाथों में असीमित ताक़त सौंप रही है और डेटा से जुड़े सारे जोखिम व नुकसान आम इंसानों के सिर पर मढ़ रही है। जिस तरह एआई कंपनियां यूज़र जनरेटेड कंटेंट के दम पर अरबों डॉलर का साम्राज्य खड़ा कर रही हैं, उसने यह बहस छेड़ दी है कि क्या अब सोशल मीडिया पोस्ट पर भी डेटा प्राइवेसी के सख्त अधिकार लागू होने चाहिए।
संदर्भ
1. https://tinyurl.com/2xvx7c98
2. https://tinyurl.com/27956m5t
3. https://tinyurl.com/2cfkww9r
4. https://tinyurl.com/23lqj9lp
5. https://tinyurl.com/2d8brxqu
6. https://tinyurl.com/262nmd89
7. https://tinyurl.com/269jyxfy





A. City Readerships (FB + App) - This is the total number of city-based unique readers who reached this specific post from the Prarang Hindi FB page and the Prarang App.
B. Website (Google + Direct) - This is the Total viewership of readers who reached this post directly through their browsers and via Google search.
C. Messaging Subscribers - This is the total viewership from City Portal subscribers who opted for hyperlocal daily messaging and received this post.
D. Total Viewership - This is the Sum of all our readers through FB+App, Website (Google+Direct), Email, WhatsApp, and Instagram who reached this Prarang post/page.
E. The Reach (Viewership) - The reach on the post is updated either on the 6th day from the day of posting or on the completion (Day 31 or 32) of one month from the day of posting.